I’m always interested in seeing examples like this where the LLM will get to a right answer after a series of questions (with no additional information) about its earlier wrong responses. I’d love to understand what’s going on in the software that allows the initial wrong answers but gets the eventually right one without an additional input.
One hypothesis is that having more tokens to process lets it “think” longer. Chain of Thought prompting where you ask the LLM to explain its reasoning before giving an answer works similarly. Also, LLMs seem to be better at evaluating solutions than coming up with them, so there is a Tree of Thought technique, where the LLM is asked to generate multiple examples of a reasoning step then pick the “best” reasoning for each reasoning step.
Take the goat over
Return empty-handed
Take the cabbage over
Return with the goat
Take wolf over
Return empty-handed
Take other wolf over
AROOOOO BROTHERS CRANK THEM HOGS


{kind=link}
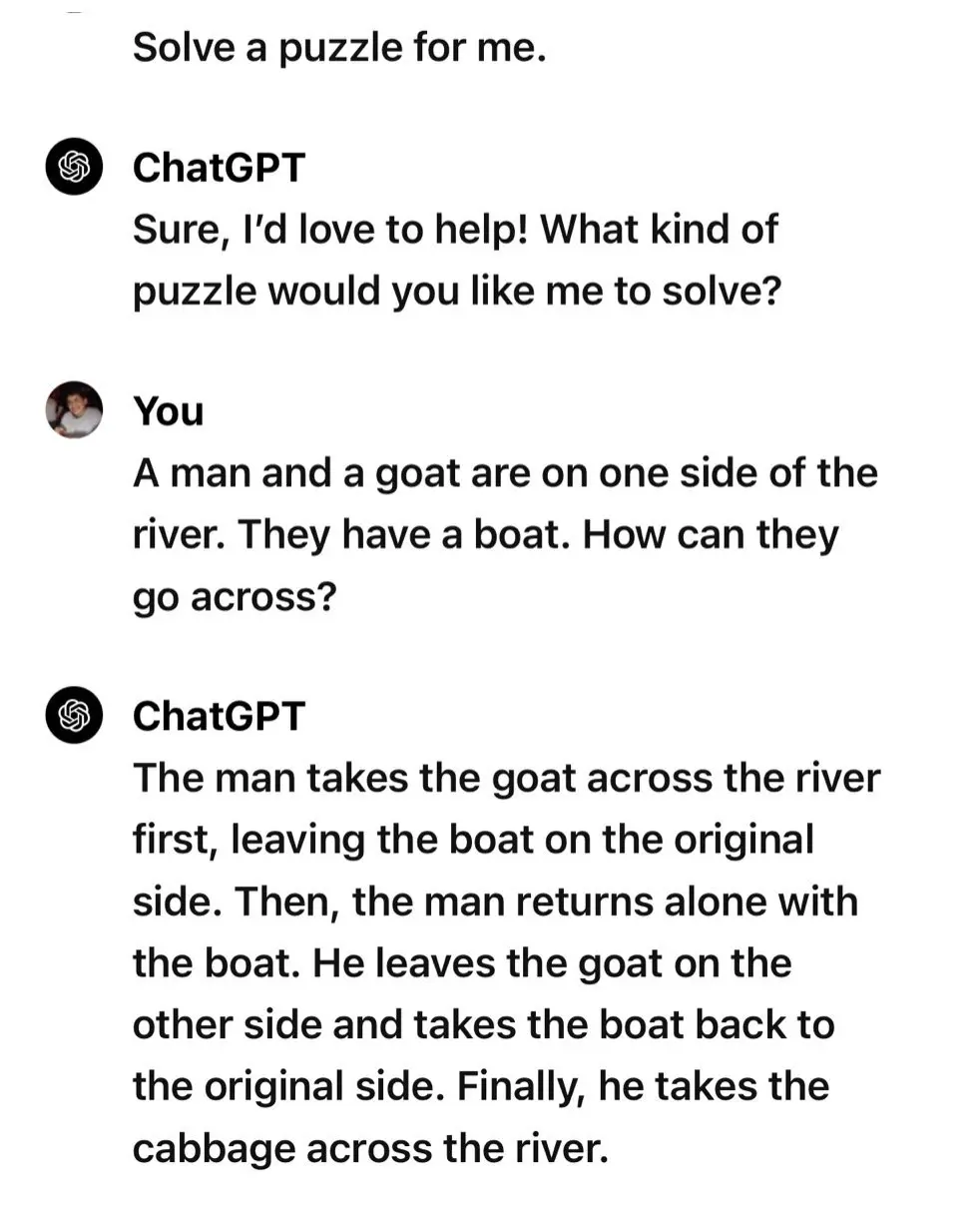
My attempt - it got there in the end at least
Looks like copilot with gpt-4 turbo got it. I was a little sad to not get a silly answer tbh
4o didn’t get it for me.
Honestly my answer felt super canned, like someone had asked it before and reported the answer as bad, so that doesn’t surprise me
I’m always interested in seeing examples like this where the LLM will get to a right answer after a series of questions (with no additional information) about its earlier wrong responses. I’d love to understand what’s going on in the software that allows the initial wrong answers but gets the eventually right one without an additional input.
One hypothesis is that having more tokens to process lets it “think” longer. Chain of Thought prompting where you ask the LLM to explain its reasoning before giving an answer works similarly. Also, LLMs seem to be better at evaluating solutions than coming up with them, so there is a Tree of Thought technique, where the LLM is asked to generate multiple examples of a reasoning step then pick the “best” reasoning for each reasoning step.
Take the goat over
Return empty-handed
Take the cabbage over
Return with the goat
Take wolf over
Return empty-handed
Take other wolf over
AROOOOO BROTHERS CRANK THEM HOGS
The last reply feels like a human took over to answer so you would stop asking the question.