

{kind=link}
It’s about asking, “how does this algorithm behave when the number of elements is significantly large compared to when the number of elements is orders of magnitude larger?”
Big O notation is useless for smaller sets of data. Sometimes it’s worse than useless, it’s misguiding. This is because Big O is only an estimate of asymptotic behavior. An algorithm that is O(n^2) can be faster than one that’s O(n log n) for smaller sets of data (which contradicts the table below) if the O(n log n) algorithm has significant computational overhead and doesn’t start behaving as estimated by its Big O classification until after that overhead is consumed.
#computerscience
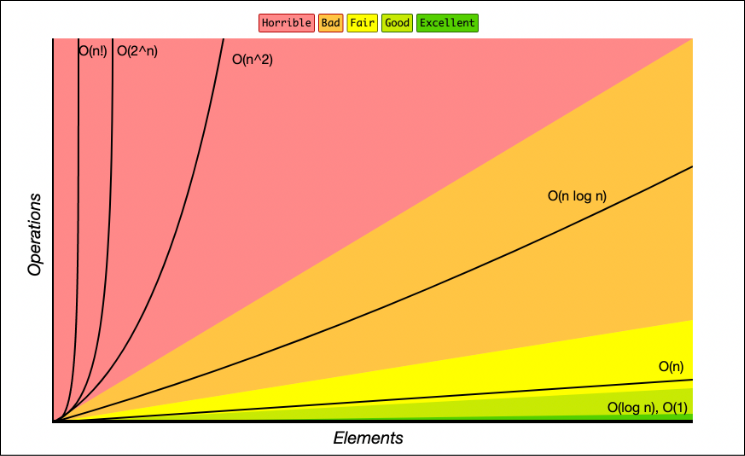
Image Alt Text:
"A graph of Big O notation time complexity functions with Number of Elements on the x-axis and Operations(Time) on the y-axis.
Lines on the graph represent Big O functions which are are overplayed onto color coded regions where colors represent quality from Excellent to Horrible
Functions on the graph:
O(1): constant - Excellent/Best - Green
O(log n): logarithmic - Good/Excellent - Green
O(n): linear time - Fair - Yellow
O(n * log n): log linear - Bad - Orange
O(n^2): quadratic - Horrible - Red
O(n^3): cubic - Horrible (Not shown)
O(2^n): exponential - Horrible - Red
O(n!): factorial - Horrible/Worst - Red"
While I get your point, you’re still slightly misguided.
Sometimes for a smaller dataset an algorithm with worse asymptomatic complexity can be faster.
Some examples:
Big O notation only considers the largest factor. It is still important to consider the lower order factors in some cases. Assume the theoretical time complexity for an algorithm A is 2nlog(n) + 999999999n and for algorithm B it is n^2 + 7n. Clearly with a small n, B will always be faster, even though B is O(n^2) and A is O(nlog(n)).
Sorting is actually a great example to show how you should always consider what your data looks like before deciding which algorithm to use, which is one of the biggest takeaways I had from my data structures & algorithms class.
This youtube channel also has a fairly nice three-part series on the topic of sorting algorithms: https://youtu.be/_KhZ7F-jOlI?si=7o0Ub7bn8Y9g1fDx